
11·
2 days ago
Essentially, verifiability (the token exists on the blockchain), de-duplication (each token can only exist once on the blockchain), and proof of ownership (only one account number can be associated with each token on the blockchain). There’s nothing wrong with this idea in a technical sense and it could be useful for some things.
But… the transaction process is computationally expensive. For the transaction to be trustworthy, many nodes on the blockchain network must process the same transaction, which creates a whole bunch of issues around network scaling and majority control and real-world resource usage (electricity, computer hardware, network infrastructure, cooling, etc).
And beyond that, the nature of society and economics created a community around this unregulated financial market that was filled with… well, exactly the kind of people you’d expect would be most interested in an unregulated financial market - scammers, speculative investors, thieves, illegal bankers, exploitatitive gambling operators, money launderers, and criminals looking to get paid without the government noticing.
The technology can solve some interesting problems around verifying that a particular digital file is unique/original (which can be useful, because it’s extremely easy to make copies of digital information) but it creates a long list of other problems as a side effect.

Is “dragged” the new “slammed”?
Hmm…
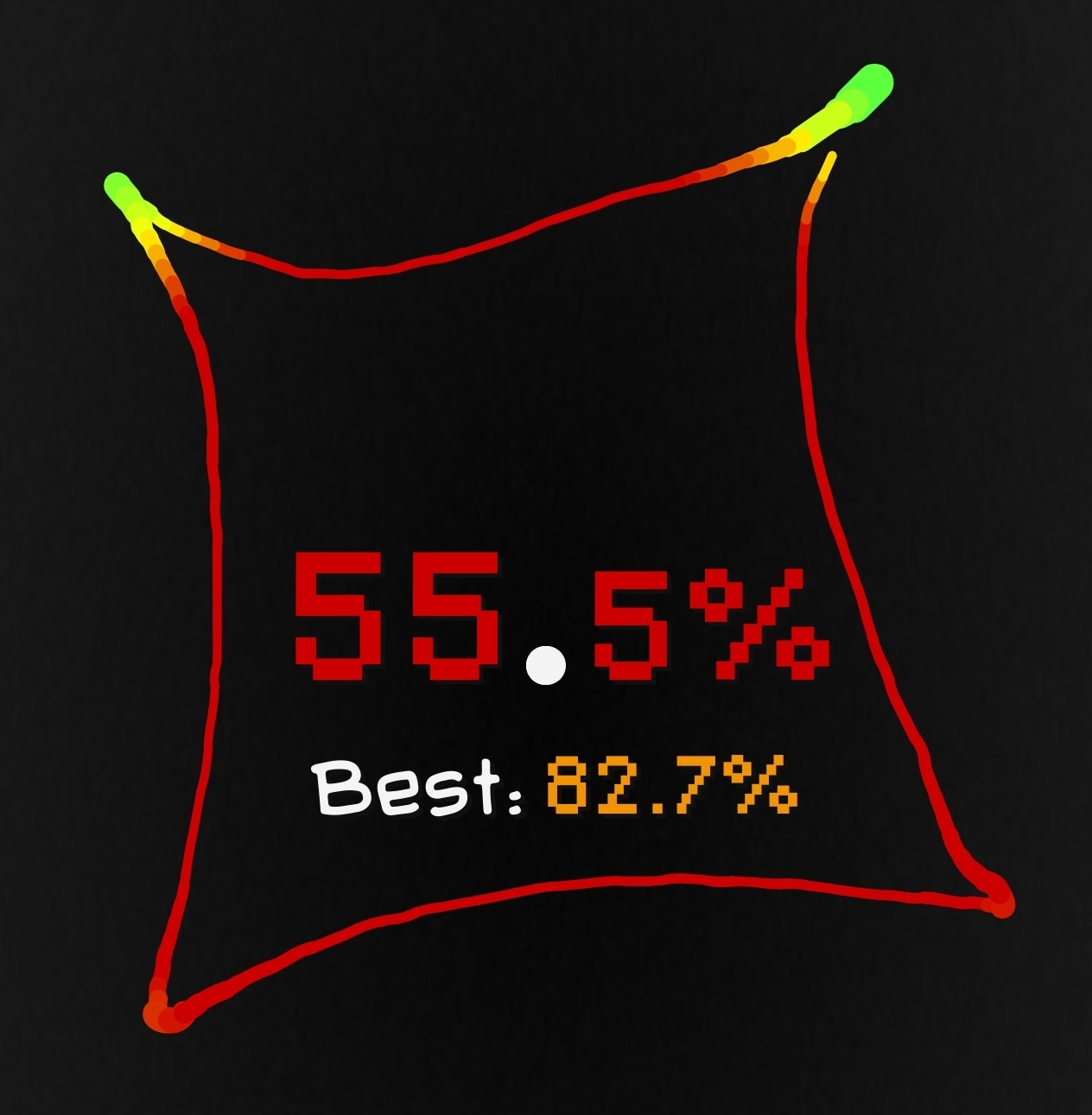
I have questions.

How low can you go?

- a few git repos (pushed and backup in the important stuff) with all docker compose, keys and such (the 5%)
Um, maybe I’m misunderstanding, but you’re storing keys in git repositories which are where…?
And remember, if you haven’t tested your backups then you don’t have backups!

I highly recommend Teaching Tech’s 3D Printer Calibration site. Some of it will not apply to your SV08 and some of it you will have to adjust to work with your printer, but it is a great overall step-by-step process with tools to generate various test models for tuning specific aspects of print quality.
It will take as long as it takes.
Dax would never
There is some benefit in allowing the fascists to publicly self-identify, but the benefit depends on the rest of the public responding with immediate and unequivocal rejection and ridicule.

You jest but… delay line memory

Anathem by Neal Stephenson
Stories of Your Life and Others by Ted Chiang
The Caves of Steel by Isaac Asimov
Cat’s Cradle by Kurt Vonnegut, Jr.
The Godmakers by Frank Herbert
Self-Reference ENGINE by Toh EnJoe
*Bonus: Low (comic series) from Image
Yeah but the current build of libvegs has some conflicts with libfruit, so if you need to use both you have to build libvegs in a different directory and then simlink it in /lib.
pics or it didn’t happen
I see, so your argument is that because the training data is not stored in the model in its original form, it doesn’t count as a copy, and therefore it doesn’t constitute intellectual property theft. I had never really understood what the justification for this point of view was, so thanks for that, it’s a bit clearer now. It’s still wrong, but at least it makes some kind of sense.
If the model “has no memory of training data images”, then what effect is it that the images have on the model? Why is the training data necessary, what is its function?
the presentation and materials viewed by 404 Media include leadership saying AI Hub can be used for “clinical or clinical adjacent” tasks, as well as answering questions about hospital policies and billing, writing job descriptions and editing writing, and summarizing electronic medical record excerpts and inputting patients’ personally identifying and protected health information. The demonstration also showed potential capabilities that included “detect pancreas cancer,” and “parse HL7,” a health data standard used to share electronic health records.
Because as everyone knows, LLMs do a great job of getting specific details correct and always produce factually accurate output. I’m sure this will have no long term consequences and benefit all the patients greatly.
We’re not talking about a “style”, we’re talking about producing finished work. The image generation models aren’t style guides, they output final images which are produced from the ingestion of other images as training data. The source material might be actual art (or not) but it is generally the product of a real person (because ML ingesting its own products is very much a garbage-in garbage-out system) who is typically not compensated for their work. So again, these generative ML models are ripoff systems, and nothing more. And no, typing in a prompt doesn’t count as innovation or creativity.
And what is it you think I don’t understand?






